We work on hardware design for computing, communications and machine intelligence. Towards the goal of designing the most efficient and high-performance hardware, we make use of all possible tools: algorithm, architecture, circuits and even substrates. Below is an overview of some of our recent research directions.
Accelerators for Machine Learning (ML) Workloads
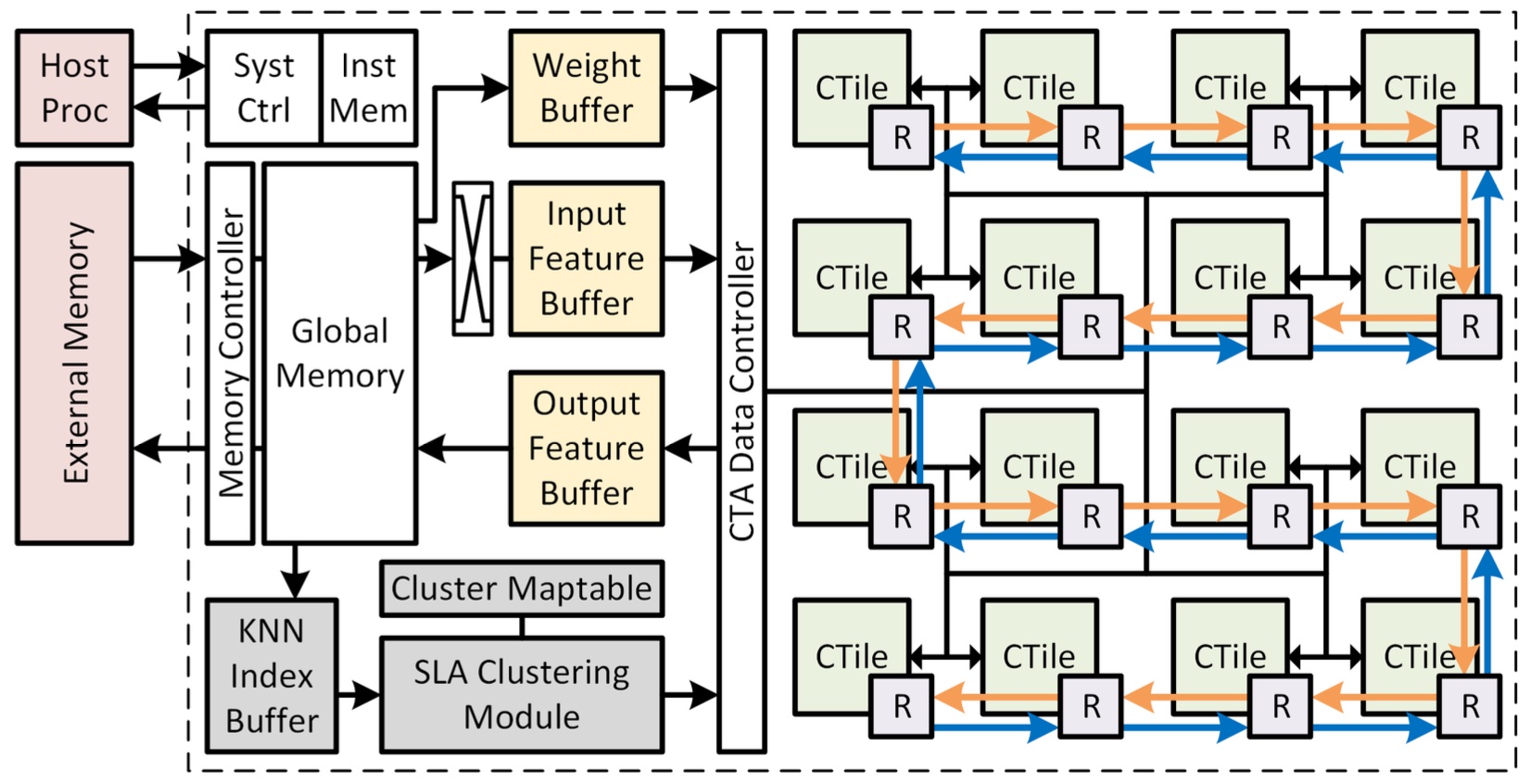
We are interested in exploring new ML methods and new ML applications to identify critical bottlenecks that require compute acceleration. Our recent work covers ML algorithms such as perception methods, tracking methods, graph neural networks, and memory-augmented neural networks, as well as ML applications on AR/VR systems with extremely constrained form factors and autonomous systems with high performance requirements. New algorithms introduce new compute kernels, flow patterns and memory access patterns that call for new architectures and microarchitectures. New applications place more stringent requirements in power, performance and area that require new thinking in application-algorithm-architecture-hardware co-designs. We investigate all these areas to advance the applications of new ML algorithms on hardware platforms.
Related recent publications (see Publications page): [J36], [J34], [J32], [J26], [C65], [C64], [C63], [C61], [C58], [C56], [C53].
Modular and Reconfigurable Hardware Systems
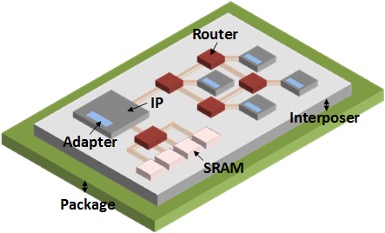
We are exploring modular construction of hardware systems using building blocks called chiplets. For the chiplet approach to succeed, we consider three key ingredients: highly reusable chiplets, efficient and high-bandwidth chiplet I/O interfaces, and advanced high-density packaging. We are constructing a diverse set of chiplets, designing fast and efficient I/O interfaces to transfer data at multi-Tbps between chiplets at substantially lower than 1 pJ/b, as well as experimenting with new packaging technologies for 2.5-dimensional and 3-dimensional integration. We are investigating not only how to quickly construct efficient hardware systems using chiplets, but also enable these systems change their personalities at a faster time scale to adapt to runtime workload changes.
Related recent publications: [C67], [C62], [C60], [C59].
High-Performance Digital Signal Processing (DSP) for Communication and Coding
The continued growth of bandwidth and energy of wireless and wireline communications rely on more sophisticated signal processing and coding methods. We are investigating DSP hardware designs for multiple-input and multiple-output (MIMO) and massive MIMO wireless communications to efficiently remove interference to achieve close to the theoretical optimal performance. We are also investigating hardware designs for near-capacity forward error correction (FEC) schemes, such as polar codes, low-density parity-check codes, and Turbo product codes, to get even closer to the ultimate limit in reliable communications using the least energy. Our work has led to some of the state-of-the-art DSP and FEC chip designs.
Related recent publications: [J33], [J31], [J28], [J25], [C66], [C55].
